



[PL version] Bezpieczeństwo danych przy użyciu narzędzi AI w pracy kupieckiej
Narzędzia AI to nie tylko wzrost produktywności do codziennej pracy kupieckiej, ale także ryzyko związane z wyciekiem poufnych danych.

Wykonując analizy trzeba pamiętać, że niektóre z nich nie powinny opuszczać sieci firmowej, a groźba związana z ich wyciekiem paradoksalnie jest większa niż na pierwszy rzut się wydaje.
Dlatego też trzeba zachować kilka środków ostrożności.
A po co o tym mówić?
Zacznijmy od początku, czyli od tego dlaczego taka ochrona na poziomie użytkownika jest ważna.
Użycie narzędzi AI w codziennej pracy kupieckiej niesie ze sobą – realne – ryzyko związane z możliwością nieautoryzowanego dostępu do poufnych informacji.
W jaki sposób?
Ano na przykład w taki jak w marcu 2023, gdzie użytkownicy ChataGPT mogli przeczytać nieswoje tytuły konwersacji w wyniku błędu bazy danych OpenAI.
Łatwo sobie wyobrazić sytuację, gdzie przypadkowo przedstawiciel dostawcy dostaje dostęp do naszej analizy robionej w AI.
Choć – bądźmy szczerzy – prawdopodobieństwo wystąpienia takie zjawiska jest bardzo niskie, to wciąż ono istnieje.
I należy to mieć w pamięci.
Dwie podstawowe strategie ochrony
W zasadzie istnieją dwa sposoby, które każdy z nas na swoim indywidualnym poziomie powinien robić używając narzędzi AI.
Są to maskowanie danych i pseudonimizacja.
Maskowanie danych jest techniką, gdzie wrażliwe informacje są ukrywane lub zastępowane symbolami. Jest to szczególnie przydatne przy analizie dokumentów, takich jak na przykład umowy handlowe, gdzie dane osobowe, kary umowne czy prawa i obowiązki stron mogą być wrażliwą tajemnicą firmy.
Pseudonimizacja polega na zamianie danych na aliasy, pozwalając zachować ogólną strukturę informacji, ale uniemożliwiając identyfikację ich źródła. Metoda ta sprawdzi się na przykład w analizie arkuszy danych, gdzie ważne jest, aby na podstawie trendów móc wyciągać wnioski, nie ujawniając przy tym szczegółów.
Praktyczne zastosowanie maskowania danych
No i właśnie w kontekście umów pokaże przykład maskowania danych.
To właśnie w nich bezpieczeństwo informacji jest niezwykle istotne, gdyż dane takie jak ceny, warunki płatności, dostawy, szczególne uzgodnienia komercyjne mogą kierować na konkretną firmę.
Weźmy na przykład standardowy wzór umowy dostępny na stronie poradnikprzedsiębiorcy.pl z uzupełnionymi przeze mnie fikcyjnymi danymi:

Jak mogłaby wyglądać taka umowa z zamaskowanymi danymi?

Oczywiście jest to bardzo uproszczony przykład, ale chodzi o pokazanie idei. Wyczyszczenie tekstu umowy z czegokolwiek co mogłoby naprowadzać na konkretną firmę jest bardzo istotne.
Warto także pamiętać o dodatkowej ostrożności i maskowaniu także tych zapisów umowy, które mogą nieść ze sobą ryzyko identyfikacji firmy.
Pseudonimizacja – jak może wyglądać?
Pseudonimizacja danych liczbowych, przydatna jest zwłaszcza przy analizie arkuszy danych. Umożliwia zachowanie poufności informacji przy jednoczesnym wykorzystaniu ich do analizy trendów i ogólnej sytuacji.
Oto przykładowa oryginalna lista materiałowa:

Zawiera konkretne informacje na temat komponentu, jego dostawcy oraz ceny.
Wiedząc ilu mamy dostawców oraz ile komponentów łatwo możemy wygenerować aliasy bez zdradzania o co chodzi. Oto przykład dla komponentów…:

…i dostawców
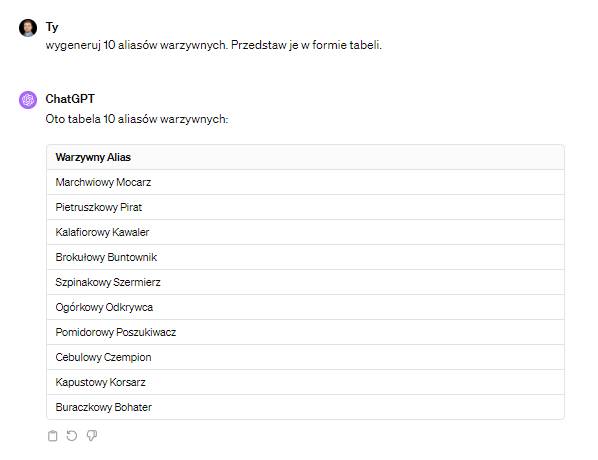
Teraz wystarczy przekleić dane przy użyciu funkcji vlookup (wyszukaj.pionowo) i gotowe.
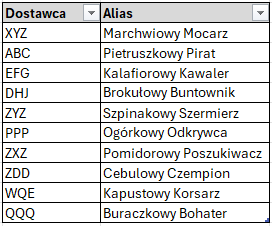
Tabela pomocnicza dla vlookup nazw dostawców z usuniętymi duplikatami
A co z ceną?
Do cen dodałem wymyślony przez siebie mnożnik: 785. Można w tym miejscu dać dowolną liczbę i działanie. Grunt, żeby nie było ono oczywiste i łatwe do odgadnięcia dla osoby postronnej.
Finalna przykładowa tabela będzie wyglądała tak:

W ten sposób pomarańczowe kolumny można bez obaw wkleić do narzędzia i dokonać analityki.
Do poczytania i przemyślenia
· Raport Deliotte: Preserving Privacy in Artificial Intelligence Applications through Anonymization of Sensitive Data
· Czy pseudonimizacja oraz anonimizacja ma sens w mojej pracy, czy może jednak wolę robić to tradycyjnie?